Columnar Storage Formats: Parquet vs. ORC
Introduction

Traditional row-based file formats work well for OLTP databases but struggle with OLAP workloads due to the following limitations:
- Sequential Reading: To read the 8th column, you must first read all preceding columns. There’s no direct access to specific columns.
- Inefficient Compression: Since values are scattered across rows, it’s hard to apply compression techniques effectively, leading to larger file sizes.
A fully column-oriented format isn’t ideal either, as retrieving entire rows becomes inefficient. The Hadoop community addressed these issues with hybrid row-column formats, leading to the development of RCFile, which later evolved into more optimized formats like ORC and Parquet.
Hybrid Row-Column Formats: RCFile, ORC, and Parquet
RCFile partitions tables horizontally into row groups and stores columns within these groups. It uses lazy decompression to speed up reads by filtering data before fully decoding it.
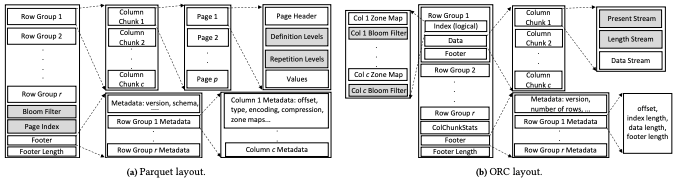
ORC and Parquet improved upon RCFile with more advanced features. Both formats:
- Partition data into row groups.
- Store data column-by-column within each row group, enabling vectorized processing while minimizing the overhead of reconstructing rows.
Format Layout
The layouts of Parquet and ORC are similar, but they differ in how they map logical blocks to physical storage:
- Parquet: Row-group size is based on the number of rows. While it supports vectorized processing, it may require more memory.
- ORC: Uses a fixed stripe size (64 MB) for better memory control but can lead to fewer entries if columns have large attributes.
Encoding Techniques
Both formats utilize compression and encoding to optimize storage:
- Parquet: Uses Dictionary Encoding, RLE, and Bitpacking. It applies dictionary encoding to all data types by default and adds integer encoding on top. Parquet avoids Delta and Frame of Reference (FOR) encoding to preserve local patterns.
- ORC: Offers more aggressive encoding options, including RLE, Dictionary Encoding (only for strings), Bitpacking, Delta encoding (for monotonically changing values), and PFOR (for outliers). It also uses rule-based algorithms for integer encoding and supports fallback mechanisms based on NDV ratios.
Compression
Both formats use block-level compression by default:
- Parquet: Allows customization of compression level and decompression speed.
- ORC: Provides configurations optimized either for file size or speed.
Type System
- Parquet: Supports primitive types like INT32 and FLOAT, and complex types built using them.
- ORC: Implements dedicated readers and writers for each type, leading to more efficient handling.
Nested Data Model
Both formats handle semi-structured data like JSON and Protocol Buffers:
- Parquet: Stores atomic fields separately, embedding non-atomic information (repetition and definition levels) within those fields.
- ORC: Encodes nested data using presence and length models, with additional boolean columns for optional fields and integer columns for repeated lengths.
While Parquet reads fewer columns, its larger file sizes stem from the duplication of non-atomic field information. ORC, on the other hand, uses dedicated columns for non-atomic fields, offering more efficient storage.
